


Machine learning has already become a crucial component in the operation of contemporary organisations and services. It is used across many sectors, including ecommerce marketing, social media, healthcare, and finance, among others. However, the process of training and implementing a machine learning model varies based on the specific task and the data available.
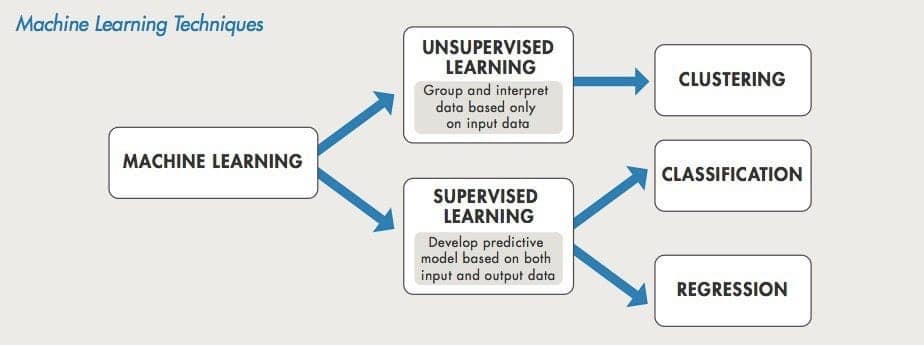
Supervised and unsupervised learning represent two distinct methods of machine learning model deployment. They vary in their training techniques and the nature of the data needed for training. Each method has its advantages, leading to differences in the suitability of supervised versus unsupervised learning for different tasks or problems.
As the use of machine learning technology increases, it’s crucial to grasp the fundamental distinctions between supervised and unsupervised learning. When an organisation decides to implement a machine learning model, the decision is influenced by the data at hand and the issue that requires a solution.
Understanding Supervised Learning
In supervised machine learning, the process involves using labelled data for both input and output during the training stage of the machine learning model’s life cycle. This training data is typically prepared by a data scientist during the initial setup phase, which is then utilised for both training and testing the model.
Once the model has grasped the connection between the input and output data, it is capable of categorising new, previously unseen data and forecasting results. The term “supervised machine learning” stems from the fact that a portion of this method necessitates human guidance. The majority of the data available is unstructured, raw data. It usually requires human input to correctly label data suitable for supervised learning. Consequently, this process can be quite demanding, as it demands a significant volume of accurately labelled training data.
In supervised machine learning, algorithms are guided to categorise data that has not been seen before and to predict future trends and changes by acting as a predictive model. These models, created with supervised machine learning, become adept at identifying objects and the characteristics that distinguish them.
They are frequently prepared using supervised machine learning methods. Through identifying patterns between input and output data, supervised machine learning models are capable of forecasting results from data that has not been previously encountered. This application could involve predicting shifts in property values or shifts in consumer buying patterns.
Understanding Unsupervised Learning
Unsupervised machine learning involves training models using raw, unlabelled data. It’s commonly employed to spot patterns and trends in unstructured data or to group similar data into predetermined categories. This method is frequently utilized in the initial stages of data exploration to gain a deeper understanding of the data.
As its name indicates, unsupervised machine learning adopts a more autonomous approach in comparison to supervised machine learning. While a human determines the model’s parameters, such as the number of clusters, the model efficiently processes vast amounts of data without direct human intervention. Consequently, unsupervised machine learning is ideal for uncovering hidden trends and relationships within the data itself. However, due to the reduced need for human intervention, it’s crucial to ensure that the results of unsupervised machine learning are interpretable.
Most of the data that’s out there is in its raw, unprocessed form. By grouping data based on shared characteristics or examining datasets for hidden trends, unsupervised learning serves as a strong method for extracting understanding from this data. On the other hand, supervised machine learning requires a lot of resources due to the necessity of having labelled data.
Supervised vs Unsupervised Learning Comparison
The primary distinction between supervised and unsupervised learning lies in the requirement for labelled training data. Supervised machine learning depends on data that is labelled with both input and output, while unsupervised learning works with data that is either unlabeled or in raw form. In supervised machine learning, the algorithm is trained to understand the connection between the labelled input and output data.
The model is adjusted until it can reliably forecast the results of data it hasn’t seen before. However, creating labelled training data can be quite costly. Conversely, unsupervised learning learns from data that is unlabeled or in its raw state. An unsupervised model identifies relationships and patterns within this unlabeled data, making it a common approach for uncovering natural trends within a dataset.
In summary, supervised and unsupervised machine learning differ in how they train and the kind of data their models absorb. However, these differences also lead to variations in their practical uses and unique capabilities. Supervised machine learning models are typically employed to forecast results for data they haven’t seen before.
This might involve predicting changes in property values or gauging the emotion behind a message. These models are also applied to categorise new data based on patterns they’ve been taught. Conversely, unsupervised machine learning methods are mainly used to uncover patterns and trends in data that haven’t been labelled. This could involve grouping data based on similarities, and differences or pinpointing hidden patterns in datasets. Unsupervised machine learning can be applied to group customer information for marketing purposes, or to spot irregularities and anomalies.
The main differences between supervised vs unsupervised learning include:
- The need for labelled data in supervised machine learning.
- The problem the model is deployed to solve. Supervised machine learning is generally used to classify data or make predictions, whereas unsupervised learning is generally used to understand relationships within datasets.
- Supervised machine learning is much more resource-intensive because of the need for labelled data.
- In unsupervised machine learning it can be more difficult to reach adequate levels of explainability because of less human oversight.
One key distinction between supervised and unsupervised learning is the types of problems these models are designed to tackle. While both categories of machine learning models derive knowledge from their training data, the capabilities of each method are best suited for specific tasks.
Supervised learning focuses on understanding the link between inputs and outputs, utilising labelled training data to classify new information or forecast outcomes. Conversely, unsupervised learning excels at discovering hidden patterns and connections within raw, unlabeled data. This characteristic makes it particularly effective for initial data exploration, dividing datasets into groups or clusters, and projects aimed at uncovering how different data attributes relate to each other for the creation of automated recommendation systems.
In machine learning, a classification task occurs when a system is employed to determine if data is categorised as belonging to a recognized category or type of object. The system assigns a category label to the data it analyzes, which the algorithm acquires by being trained on data that is already labelled. The data’s input and output have been marked, allowing the system to comprehend which characteristics will identify an object or data point with various category labels. The requirement for labelled data during the training stage indicates that this is a supervised machine-learning approach.
There are different types of classification problems, which are generally different depending on the count of class labels that are applied to the data in a live environment.
The main classification problems include:
- Binary classification
- Multiple class classification
- Multiple label classification
Binary classification
Binary classification is when a model can apply only two class labels. A popular use of a binary classification would be in detecting and filtering junk emails. A model can be trained to label incoming emails as either junk or safe, based on learned patterns of what constitutes a spam email.
Binary classification is commonly performed by algorithms such as:
- Logistic Regression
- Decision Trees
- Naïve Bayes
Multiple class classification
Multiple class classification is when models reference more than the two class labels found in binary classification. Instead, there could be a huge array of possible class labels that could be applied to the object or data. An example would be in facial recognition software, where a model may analyse an image against a huge range of possible class labels to identify the individual.
Multiple class classification is commonly performed by algorithms such as:
- Random Forest
- k-Nearest Neighbours
- Naive Bayes
Multiple label classification
Multiple label classification is when an object or data point may have more than one class label assigned to it by the machine learning model. In this case, the model will usually have multiple outputs. An example could be in image classification which may contain multiple objects. A model can be trained to identify, classify and label a range of subjects in one image.
Multiple label classification is commonly performed by algorithms such as:
- Multiple-label Gradient Boosting
- Multiple-label Random Forests
- Using different classification algorithms for each class label
Supervised learning regression
A frequent application of supervised machine learning models is in the field of predictive analytics. Regression is often employed as the method for a machine learning model to forecast continuous results. A supervised machine learning model acquires the ability to recognise patterns and connections in a dataset that has been labelled for training. After comprehending the link between the input data and the desired output data, the model can handle new and previously unknown data. Thus, regression plays a crucial role in predictive machine learning models, which can be utilised for:
- Forecasting stock or trading outcomes and market fluctuations is a key role of machine learning in finance.
- Predict the success of marketing campaigns so organisations can assign and refine resources.
- Forecast changes in market value in sectors like retail or the housing market.
- Predict changes in health trends in a demographic or area.
Common algorithms used in supervised learning regression include:
- Simple Linear Regression
- Decision tree Regression
Simple Linear Regression
Simple Linear Regression is a popular type of regression approach and is used to predict target output from an input variable. A linear connection between the input and target output should be present. Once a model has been trained on the relationship between the input and target output, it can be used to make predictions on new data. Examples might be predicting salary based on age and gender.
Decision Tree Regression
As the name suggests, Decision Tree models take the structure of a tree in which the model incrementally branches. Decision Trees are a popular form of supervised machine learning and can be used for both regression and classification. The dataset is broken down into incremental subsets and can be used to understand the correlation between independent variables. The resulting model can then be used to predict output based on new data.


