


Deep learning is the field of artificial intelligence (AI) that teaches computers to process data in a way inspired by the human brain. Deep learning models can recognise data patterns like complex pictures, text, consumer buying habits, repeat frequency, pathways and sounds to produce accurate insights and predictions.
A neural network is the underlying technology in deep learning. It consists of interconnected nodes or neurons in a layered structure. The nodes process data in a coordinated and adaptive system. They exchange feedback on generated output, learn from mistakes, and improve continuously. Thus, artificial neural networks are the core of a deep learning system.
Key differences: deep learning vs. neural networks
The terms deep learning and neural networks are used interchangeably because all deep learning systems are made of neural networks. However, technical details vary. There are several different types of neural network technology, and all may not be used in deep learning systems.
For this comparison, the term neural network refers to a feedforward neural network. Feedforward neural networks process data in one direction, from the input node to the output node. Such networks are also called simple neural networks.
Next are some key differences between feedforward neural networks and deep learning systems.
Architecture
In a simple neural network, every node in one layer is connected to every node in the next layer. There is only a single hidden layer.
In contrast, deep learning systems have several hidden layers that make them deep.
There are two main types of deep learning systems with differing architectures—convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
CNN architecture
CNNs have three layer groups:
- Convolutional layers extract information from data you input, using preconfigured filters.
- Pooling layers reduce the dimensionality of data, breaking down data into different parts or regions.
- Fully connected layers create additional neural pathways between layers. This allows the network to learn complex relationships between features and make high-level predictions.
You can use CNN architecture when you process images and videos, as it can handle varying inputs in dimension and size.
RNN architecture
The architecture of an RNN can be visualized as a series of recurrent units.
Each unit is connected to the previous unit, forming a directed cycle. At each time step, the recurrent unit takes the current input and combines it with the previous hidden state. The unit produces an output and updates the hidden state for the next time step. This process is repeated for each input in the sequence, which allows the network to capture dependencies and patterns over time.
RNNs excel at natural language functions like language modelling, speech recognition, and sentiment analysis.
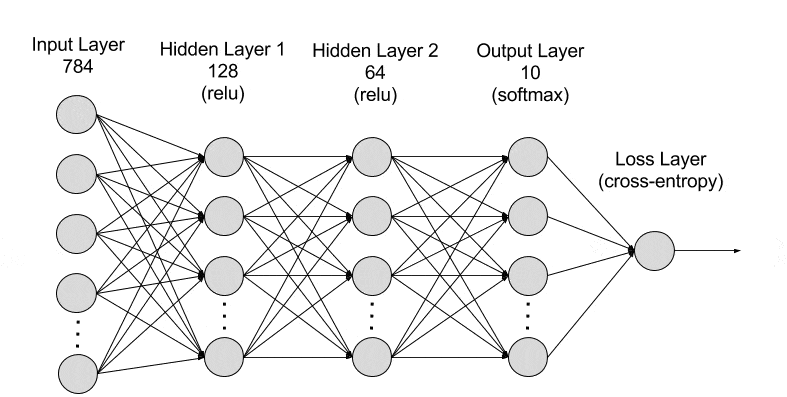
Complexity
Every neural network has parameters, including weights and biases associated with each connection between neurons. The number of parameters in a simple neural network is relatively low compared to deep learning systems. Hence, simple neural networks are less complex and computationally less demanding.
In contrast, deep learning algorithms are more complicated than simple neural networks as they involve more layers of nodes. For example, they can selectively forget or retain information, which makes them useful for long-term data dependencies. Some deep learning networks also use autoencoders.
Autoencoders have a layer of decoder neurons that detect anomalies, compress data, and help with generative modelling. As a result, most deep neural networks have a significantly higher number of parameters and are computationally very demanding.
Thanks to its fewer layers and connections, you can train a simple neural network more quickly. However, their simplicity also limits the extent to which you can teach them. They cannot perform complex analysis.
Deep learning systems have a much greater capacity to learn complex patterns and skills. Using many different hidden layers, you can create complex systems and train them to perform well on complex tasks. That being said, you will need more resources and larger datasets to achieve this.
Performance
Feedforward neural networks perform well when solving basic problems like identifying simple patterns or classifying information. However, they will struggle with more complex tasks.
On the other hand, deep learning algorithms can process and analyze vast data volumes due to several hidden layers of abstraction. They can perform complex tasks like natural language processing (NLP) and speech recognition.
Practical applications: deep learning vs. neural networks
You often use simple neural networks for machine learning (ML) tasks due to their low-cost development and accessible computational demands. Organisations can internally develop applications that use simple neural networks. They’re more feasible for smaller projects because they have limited computational requirements. If a company needs to visualise data or recognise patterns, neural networks provide a cost-effective way of creating these functions.
On the other hand, deep learning systems have a wide range of practical uses. Their ability to learn from data, extract patterns, and develop features allows them to offer state-of-the-art performance. For example, you can use deep learning models in natural language processing (NLP), autonomous driving, and speech recognition.
However, you need extensive resources and funding to train and self-develop a deep learning system. Instead, organisations prefer using pre-trained deep learning systems as a fully managed service they can customise for their applications.
Summary of differences: deep learning systems vs. neural networks



