
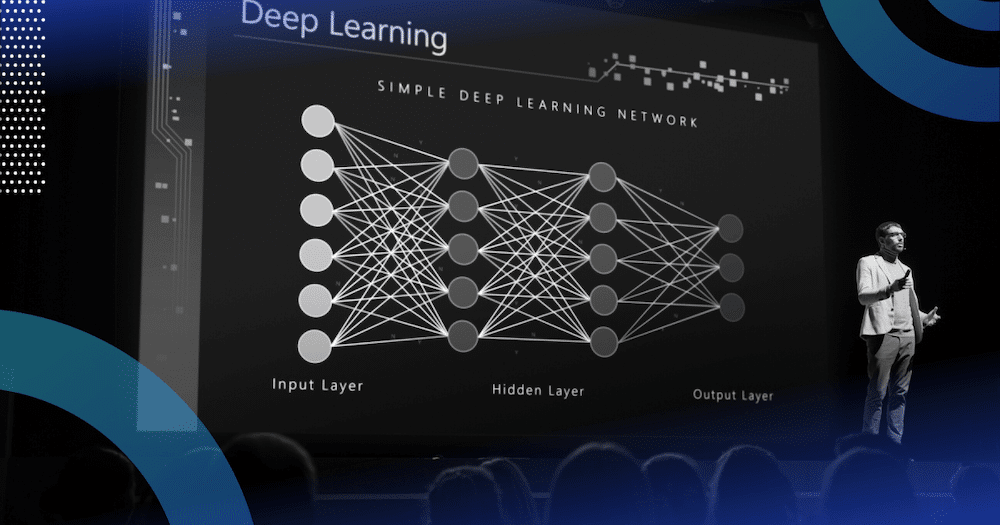
Deep learning is all the rage today, as breakthroughs in the field of artificial neural networks in the past few years have driven companies across industries to implement deep learning solutions as part of their AI strategy. From hyper-personalised product selections to image and copy creation and object recognition in retail, and much more, deep learning has unlocked a myriad of sophisticated new AI applications. But is it always the right way to go?
The outstanding performance of deep learning algorithms with complex tasks requiring huge amounts of data, combined with the increasing availability of pre-trained models on publicly available data, have made deep learning particularly appealing to many organisations in the past few years. However, this doesn’t mean that deep learning is the answer to all machine learning (ML) related problems.
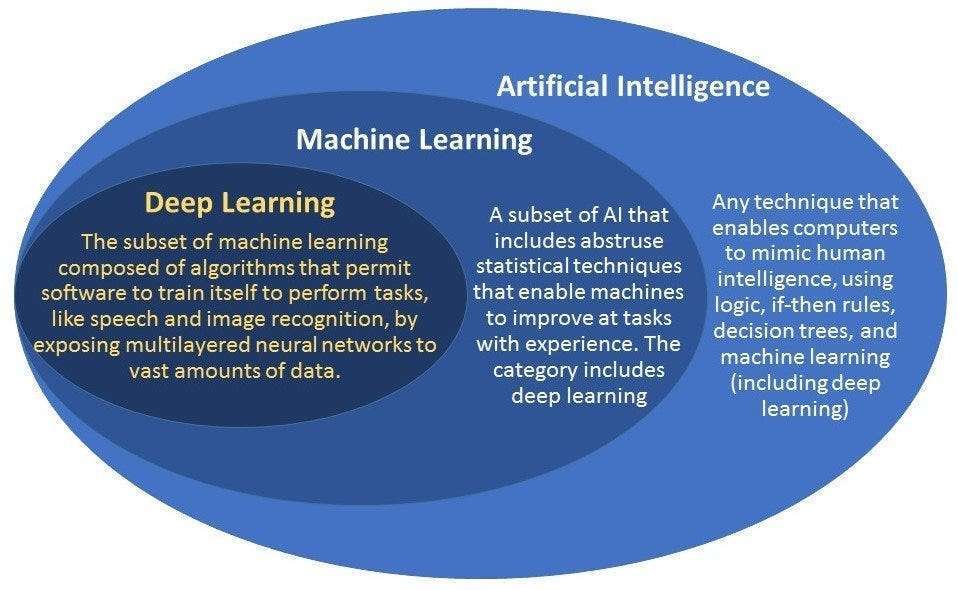
See article deep learning vs. machine learning.
But how to tell when deep learning is necessary, and when it isn’t? Each use case is very individual and will depend on your specific business objectives, AI maturity, timeline, data, and resources, among other things. Below are some of the general considerations to take into account before deciding whether or not to use deep learning to solve a given problem.
How complex is your problem?
One of the main advantages of deep learning lies in being able to solve complex problems that require discovering hidden patterns in the data and/or a deep understanding of intricate relationships between a large number of interdependent variables. Deep learning algorithms can learn hidden patterns from the data by themselves, combine them, and build much more efficient decision rules.
Deep learning shines when it comes to complex tasks, which often require dealing with lots of unstructured data, such as image classification, natural language processing, or speech recognition, among others. However, for simpler tasks that involve more straightforward feature engineering and don’t require processing unstructured data, classical machine learning may be a better option.
How important is deep learning accuracy vs. interpretability?
While deep learning reduces the human effort of feature engineering, as this is autonomously done by the machine, it also increases the difficulty for humans to understand and interpret the model. Model interpretability is one of deep learning’s biggest challenges.
When evaluating any machine learning model, there is usually a tradeoff to be made between accuracy and interpretability. Deep networks have achieved accuracies that are far beyond that of classical ML methods in many domains, but as they model very complex situations with high non-linearity and interactions between inputs, they are nearly impossible to interpret.
On the contrary, due to the direct feature engineering involved in classical ML, these algorithms are quite easy to interpret and understand. What’s more, choosing between different classical ML algorithms or tuning hyper-parameters is more straightforward since we have a more thorough understanding of the data and inner workings of the algorithms.
How much time and resources are you willing to allocate?
Despite its increasing accessibility, deep learning in practice remains a complicated and expensive endeavour. For one thing, due to their inherent complexity, the large number of layers and the massive amounts of data required, deep learning models are very slow to train and require a lot of computational power, which makes them very time- and resource-intensive. Graphics Processing Units, or GPUs, have practically become a requirement nowadays to execute deep learning algorithms. GPUs are very expensive yet without them training deep networks to high performance would not be practically feasible.
See article; Artificial Intelligence -unveiling the next frontier
Classical ML algorithms can be trained just fine with just a decent CPU (Central Processing Unit), without requiring the best of the best hardware. Because they aren’t so computationally expensive, one can also iterate faster and try out many different techniques in a shorter period.
Do you have enough quality labelled data?
Don’t think of deep learning as a model learning by itself. You still need properly labeled data and a lot of it! One of deep learning’s main strengths lies in being able to handle more complex data and relationships, but this also means that the algorithms used in deep learning will be more complex as well. And to extract general enough complex patterns from data, you will need lots – read LOTS – of examples (much more than a traditional ML model) – typically millions of labelled data points for a classification task.
The lack of a sufficiently large corpus of precisely labelled high-quality data is one of the main reasons why deep learning can have disappointing results in some business cases. Organisations face a myriad of challenges when it comes to cleaning, preparing and labelling data, and these processes often take up a massive volume of time and resources from teams that could be better spent building the next machine learning models or pushing models into production.
One way to address the cumbersome task of data labelling is through active learning, but in cases where having very large amounts of efficiently labelled data is not possible (or necessary), opting for more classical ML algorithms and models may be a better use of your data teams’ time, effort, and resources.
Conclusion
Whether you decide to go with classical machine learning, or deep learning for a certain data project, a common thread is that there should be human oversight, evaluation and decision-making involved at every step of the process. This human-in-the-loop augmented intelligence is the key to truly responsible and transparent AI.
| Classical Machine Learning: | Deep Learning: |
| Very high accuracy is a priority (and primes over straightforward interpretability and explainability). Large amounts of precisely labelled data. Complex feature engineering. Powerful compute resources available (GPU acceleration). Augmentation and other transformations of the initial dataset will be necessary. | Very high accuracy is a priority (and primes over straightforward interpretability and explainability). Large amounts of precisely labeled data. Complex feature engineering. Powerful compute resources available (GPU acceleration). Augmentation and other transformations of the initial dataset will be necessary. |
See this crucial software comparison article:
Distinctions between all the top hyper-personalisation software providers (Updated)


