

Statistical modelling is used by organisations to transform data into business insights before machine learning (ML) comes into the picture. Continuing our series of articles, this one explains most precisely how the two compare, and how can businesses decide which one is better suited to cater for their needs. Both are based on statistics.
Machine Learning is not glorified statistics
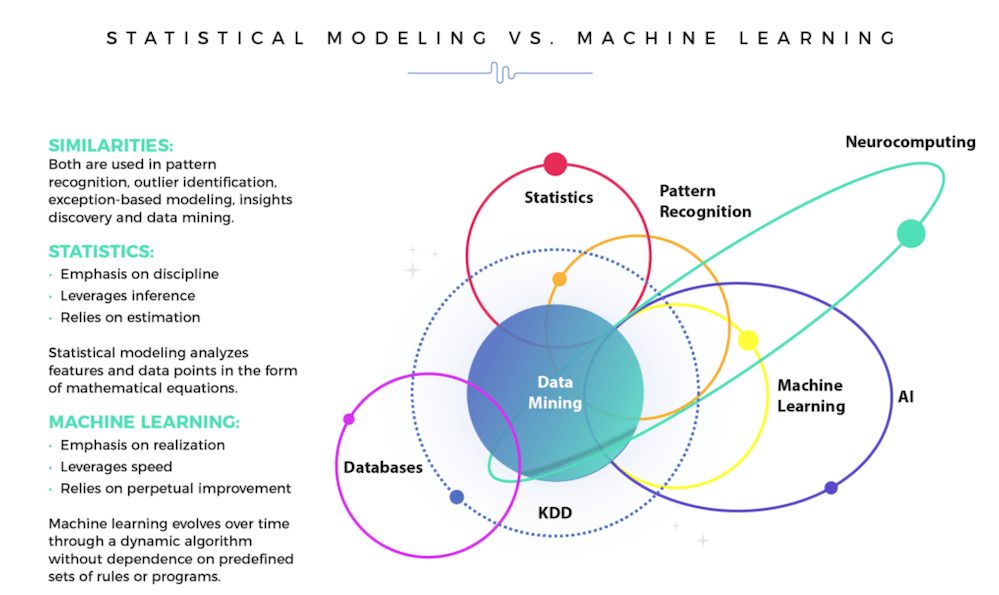
Statistics is a mathematical science which deals with the collection, analysis, interpretation or explanation, and presentation of data. Since machine learning finds patterns in large amounts of data, it is obvious that it is built upon a statistical framework.
However, ML draws upon many other fields of mathematics and computer science, for example:
- • ML theory (mathematics & statistics)
- • ML algorithms (optimisation)
- • ML implementations (computer science & engineering)
Statistical Modelling is an approximation of reality
SM is a simple mathematical function used to approximate reality and optionally to make predictions from this approximation. For example, if we want to prove that the price of a house is related to the square feet of the house, we may use a statistical model (e.g. Y=aX+b) to understand this relationship. We may collect data on 200,000 consumers and test the repeatability of the relationship involved in their product selection so that we can accurately characterise it and predict future purchases.
Differences between Statistical Modelling and Machine Learning
The biggest difference between statistics and ML is their purposes. While statistical models are used for finding and explaining the relationships between variables, ML models are built to provide accurate predictions without explicit programming. Although some statistical models can make predictions, the accuracy of these models is usually not the best as they cannot capture complex relationships between data. On the other hand, ML models can provide better predictions, but it is more difficult to understand and explain them. Admittedly where the data is vast, and perpetually updating, especially in frequent site visits or purchases, deep learning, a discipline within machine learning becomes the greater focus.
Statistical models explicitly specify a probabilistic model for the data and identify variables that are usually interpretable and of special interest, such as the effects of predictor variables. In addition to identifying relationships between variables, statistical models establish both the scale and significance of the relationship.
By contrast, ML models are more empirical. ML usually does not impose relationships between predictors and outcomes, nor isolate the effect of any single variable. Let’s go back to the consumer example. If we get the data of 20 million people with 100 clicks each, per site visit, and we mainly want to predict AOV, and relevancy of individual SKUs, we may use a machine learning model as there are so many variables. We may not understand the relationships between variables and how the model makes sense, but what we are after is accurate predictions.
How to choose SM and ML for your business?
In the business world, data analytics requires an in-depth understanding of business problems, as well as highly accurate predictions. To achieve desired results, companies need to know which situation requires which model. This depends on the input data (such as data type and data amount), the importance of understanding the relationships between variables, and ultimately on the decisions to be taken.
You can apply SM when:
- You understand specific interaction effects between variables. You have prior knowledge about their relationships, for example, before you analyse weight and height, you know there is a positive linear relationship between these two variables.
- Interpretability is important. You have to comply with strict regulations which require you to understand exactly how the models work, especially when the decision affects a person’s life.
- Your data is small. You can observe and process datasets personally. Get your data storage sorted first, it is a legal requirement (see GDPR rules and legal permissions etc), and is essential for quick and painless processing.
For example, hospitals want to identify people at risk of emergency hospital admission. It is very important to understand the characteristics of patients. These are useful information for designing intervention strategies to improve care outcomes for these patients. For instance, with patient data from a primary care rust, the analyst may choose SM to prioritise patients for preventive care.
You can apply ML when:
- High predictive accuracy is your goal. For example, if your work is for a large fashion retailer, you don’t want to accept spurious data which could jeopardise marketing ROI, so you want your predictive model to be as accurate as possible.
- Interpretability is less important. You do not care much about why a decision was made. Being able to understand the model is ideal, but not a must.
- Your data is big. You won’t be able to process the data in person. For example, retailers with a significant number of SKUs, and exacerbated the greater the number of consumers on your database.
ML is very good at non-pre-specified interactions. For example, companies usually have a massive customer database with hundreds of variables, without knowing what variables define a certain type of customer. To implement solutions to take immediate advantage of ML, from enterprise to the newest retailer, providing your front-facing nurtures frequent and perpetual custom, then solutions like hyper-personalisation for email marketing should be your primary concern, which are wholly autonomous.


