

This article introduces a selection of papers on Large Language Models (LLMs) from around the world addressing the latest technology being used to push the boundaries of data analytics. We begin with the latest paper from Renmin University China, introducing CoSearchAgent, a lightweight collaborative search agent powered by large language models that are designed as a Slack plugin to support collaborative search during multi-party conversations on that platform.
CoSearchAgent can understand queries and context within multi-user dialogues, retrieve relevant information from the web via APIs, and respond to users with answers grounded in the search results. It also supports mixed-initiative dialogue by asking clarifying questions when information needs are unclear. CoSearchAgent is released as a highly customisable open-source plugin.
📚 https://arxiv.org/abs/2402.06360
👨🏽💻 https://github.com/pygongnlp/CoSearchAgent
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
This survey paper from IITP/Amazon provides a structured overview of recent advancements in prompt engineering, the technique of using carefully designed instructions called “≈” to elicit desired behaviour from large language models (LLMs) and vision-language models (VLMs). Categorising by application area, the paper summarises and analyses 29 distinct prompting methods in detail, including their techniques, targeted models, datasets used, and strengths and limitations.
📚 https://arxiv.org/abs/2402.07927
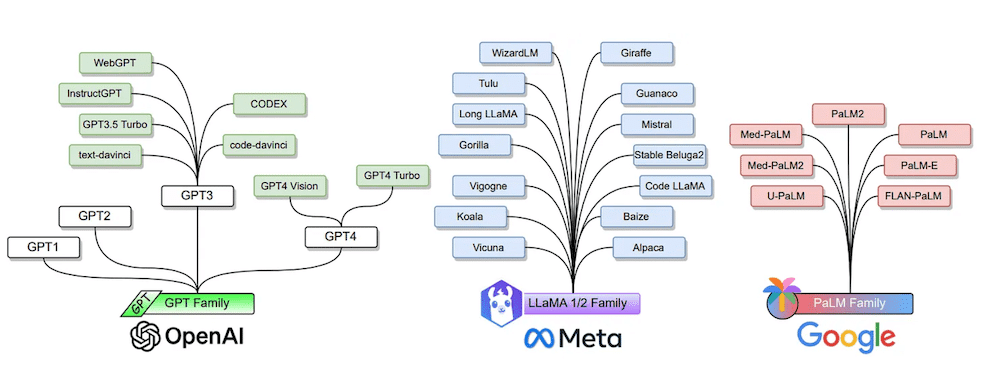
Large Language Models: A Survey
This paper surveys the recent advances in large language models (LLMs) that exhibit strong language understanding and generation capabilities as well as emergent abilities like in-context learning, instruction following, and multi-step reasoning. The paper provides an overview of prominent LLMs including the GPT, LLaMA, and PaLM families, and discusses methods for building, augmenting, and using LLMs. It also reviews popular training/evaluation datasets and metrics, compares several models’ performance, and outlines open challenges and future directions.
📚 https://arxiv.org/abs/2402.06196
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
This paper from NUS develops a question-answering framework targeting textual graphs, enabling users to “chat with their graph” using complex natural language queries. The authors propose a GraphQA benchmark with data collected from common sense reasoning, scene graphs, and knowledge graph tasks to facilitate research in the area. A new architecture called G-Retriever is introduced that combines graph neural networks, large language models, and retrieval-augmented generation to address hallucination and scalability issues.
📚 https://arxiv.org/abs/2402.07630
👨🏽💻 https://github.com/XiaoxinHe/G-Retriever
Prompt Perturbation in Retrieval-Augmented Generation-based Large Language Models
This paper from CSIRO demonstrates that retrieval-augmented generation (RAG) models can be vulnerable to factual errors when even minor prompt perturbations are introduced. The authors propose a Gradient Guided Prompt Perturbation (GGPP) technique that can systematically modify prompts to steer RAG models towards retrieving targeted false passages from a data repository, leading to factually incorrect outputs. To defend against such attacks, they reveal how GGPP perturbations alter neuron activations in RAG models and introduce a lightweight probe called ACT that leverages these activation patterns to effectively detect perturbation-induced factual errors.
📚 https://arxiv.org/abs/2402.07179
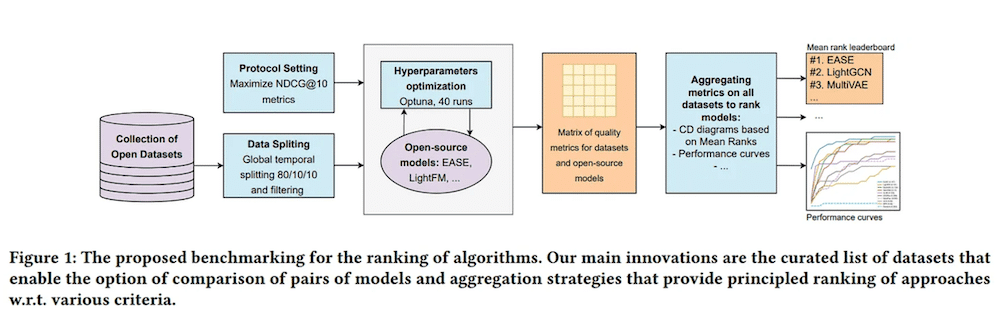
From Variability to Stability: Advancing RecSys Benchmarking Practices
This paper from Skoltech introduces a novel benchmarking methodology for evaluating and comparing recommender system algorithms across multiple datasets. Through using 30 diverse public datasets, including two newly released ones, and evaluating 11 collaborative filtering methods over 9 metrics, the authors systematically analyse the impact of dataset characteristics on performance.
📚 https://arxiv.org/abs/2402.09766
LiRank: Industrial Large Scale Ranking Models at LinkedIn
This paper concerning the large-scale ranking framework at LinkedIn presents LiRank, a large-scale deep learning ranking framework deployed at LinkedIn to enhance relevance in applications like feed, jobs, and ads. The authors propose innovations including Residual DCN layers with attention and residuals, joint isotonic calibration, productionised explore-exploit strategies, and methods to compress models for serving. By combining and tuning state-of-the-art architectures like Transformers and Dense Gating, a unified ranking model is created and optimised through techniques like incremental training and multi-task learning.
📚 https://arxiv.org/abs/2402.06859
eCeLLM: Generalising Large Language Models for Ecommerce from Large-scale, High-quality Instruction Data
This paper from OSU introduces ECInstruct, the first large-scale, high-quality benchmark instruction dataset for e-commerce. The authors use this dataset to develop eCeLLM, a series of ecommerce language models, by instruction-tuning general-purpose LLMs. Extensive experiments demonstrate that eCeLLM models substantially outperform baseline models including GPT-4 and state-of-the-art task-specific models in in-domain evaluation across 10 key e-commerce tasks. Moreover, eCeLLM exhibits excellent out-of-domain generalization ability to unseen products and instructions.
📚 https://arxiv.org/abs/2402.08831
👨🏽💻 https://ninglab.github.io/eCeLLM/
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts
This paper from Google DeepMind proposes ReadAgent, a large language model (LLM) agent system that interacts with long documents similarly to humans to increase effective context length. ReadAgent uses LLM prompting to segment documents into pages, compress pages into short episodic “gist memories”, and look up relevant passages when needed to solve tasks. This allows ReadAgent to capture both global and local context from very long documents. Evaluations on reading comprehension datasets with 3-20x longer documents show ReadAgent outperforming baselines using retrieval methods or the full long contexts directly.
📚 https://arxiv.org/abs/2402.09727
👨🏽💻 https://read-agent.github.io/
Rethinking Large Language Model Architectures for Sequential Recommendations
This paper from MSU/Amazon proposes Lite-LLM4Rec, a simplified large language model for efficient sequential recommendation. Existing LLM-based recommenders formulate all information into text and use beam search for decoding recommendations, but inference is computationally expensive. Through studies, the authors find beam search unnecessary for this task, while tokenising items causes redundancy.
Thus, Lite-LLM4Rec eliminates decoding and instead uses an item projection head to rank recommendations. It also employs a hierarchical LLM structure to efficiently handle item context. Experiments show Lite-LLM4Rec significantly improves inference efficiency (97.28% on ML-1m) and overall performance (46.8% on ML-1m) compared to prior LLM-based recommenders.
📚 https://arxiv.org/abs/2402.09543
We hope this roundup of the most recent top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.


